Një hulumtim i BIRN tregon probleme serioze në politikën e përmbajtjes të Facebook dhe Twitter në Ballkan.

Partners Serbia, një OJQ me seli në Beograd që punon me nisma për të luftuar korrupsionin dhe zhvillimin e demokracisë dhe sundimit të ligjit në vendin e Ballkanit, kishte më shumë se nëntë vjet që ishte në Twitter kur, në nëntor 2020, gjiganti i rrjeteve sociale ia pezulloi llogarinë.
Twitter nuk dha asnjë njoftim ose shpjegim për pezullimin, por Ana Toskic Cvetinovic, drejtoresha ekzekutive e Partners Serbia, kishte një ide – se kjo ishte rezultat i një “sulmi të koordinuar”, ndoshta përdorues të tjerë të Twitter kishin dërguar ankesa rreth mënyrës se si po e përdorte OJQ-ja llogarinë e saj.
“Ne u përpoqëm për ditë me radhë të merrnim të paktën disa informacione nga Twitter, si për shembull, se cili mund të jetë shkaku dhe si ta zgjidhim problemin, por nuk kemi marrë ndonjë përgjigje”, tha për BIRN Toskic Cvetinoviç. “Pas një muaji heshtje, pamë se e vetmja zgjidhje ishte hapja e një llogarie të re.”
Twitter e hoqi pezullimin në janar, përsëri pa shpjegime. Por Partners Serbia nuk është e vetmja midis OJQ-ve, organizatave të medieve dhe figurave publike në Ballkan të cilëve u janë pezulluar llogaritë në rrjetet sociale pa shpjegime të duhura ose ndonjëherë pa as edhe një shpjegim fare, sipas monitorimit të BIRN të të drejtave digjitale dhe shkeljeve të lirisë në rajon.
Ekspertët thonë se mungesa e transparencës është një problem i rëndësishëm për ata që përdorin rrjetet sociale si një kanal jetik komunikimi, jo më pak sepse ata lihen në errësirë për atë që mund të bëhet për të parandaluar pezullime të tilla në të ardhmen.
Por ndërsa organizata si Partners Serbia mund të përballen me pezullim arbitrar, gjysma e postimeve në Facebook dhe Twitter që raportohen si gjuhë urrejtjeje, që kërcënojnë dhunë ose shprehin ngacmim në gjuhën boshnjake, serbe, malazeze ose maqedonase mbeten në internet, sipas rezultateve të një studimi të BIRN pavarësisht konfirmimit nga kompanitë që postimet shkelnin rregullat.
Hulumtimi tregon se mjetet e përdorura nga gjigantët e rrjeteve sociale për të mbrojtur udhëzimet e tyre po dështojnë: postimet dhe llogaritë që shkelin rregullat shpesh mbeten të disponueshme edhe kur pranohen shkeljet, ndërsa të tjera që qëndrojnë brenda këtyre rregullave mund të pezullohen pa ndonjë arsye të qartë.
Gjetjet e BIRN janë si më poshtë:
- Pothuajse gjysma e raportimeve në gjuhën boshnjake, serbe, malazeze ose maqedonase në Facebook dhe Twitter kanë të bëjnë me gjuhë urrejtjeje
- Një në dy postime të raportuara si gjuhë urrejtjeje, kërcënuese për dhunë ose ngacmim në gjuhën boshnjake, serbe, malazeze ose maqedonase, mbetet në internet. Kur bëhet fjalë për raportime dhune kërcënuese, përmbajtja u hoq në 60 për qind të rasteve dhe 50 për qind në raste ngacmimesh të synuara.
- Facebook dhe Twitter po përdorin një model hibrid, një kombinim të inteligjencës artificiale dhe vlerësimit njerëzor në rishikimin e raportimeve të tilla, por nuk pranuan të zbulojnë se sa prej tyre janë rishikuar në të vërtetë nga një person me njohuri në gjuhën boshnjake, serbe, malazeze ose maqedonase.
- Të dy rrjetet sociale miratojnë një “qasje proaktive”, që do të thotë se ata heqin përmbajtje ose pezullojnë llogari edhe pa një raportim sjellje rë dyshimtë, por kriteret e përdorura janë të paqarta dhe mungon transparenca.
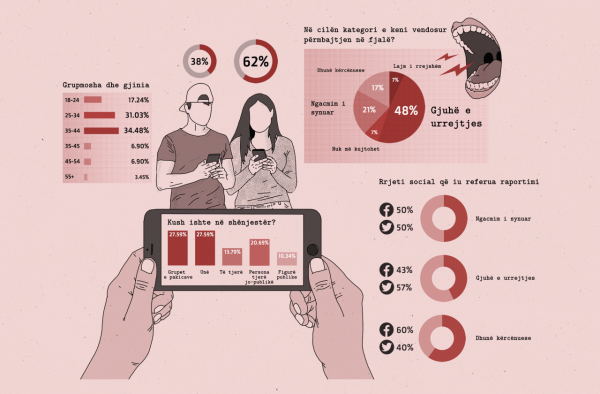
- Sondazhi tregoi se njerëzit ishin më të gatshëm të raportonin përmbajtje që synonte ata ose grupet e pakicave.
Ekspertët thonë se problemi më i madh mund të jetë mungesa e transparencës në mënyrën se si kompanitë e rrjeteve sociale vlerësojnë ankesat.
Vetë vlerësimi bëhet në shkallë të parë nga një algoritëm dhe, nëse është e nevojshme, më vonë përfshihet një person. Por hulumtimi i BIRN tregon se gjërat bëhen të çrregullta kur bëhet fjalë për gjuhët e Ballkanit, pikërisht për shkak të specifikës së gjuhës dhe kontekstit.
Dallimi i kritikës së ashpër nga shpifja ose mendimet radikale politike nga shprehja e urrejtjes dhe racizmit ose nxitja e dhunës, kërkon analizë kontekstuale dhe të nuancuar.
Gjysma e postimeve që përmbajnë gjuhë urrejtjeje mbeten në internet
Facebook dhe Twitter janë ndër rrjetet sociale më të njohura në Ballkan. Shtrirja e popullaritetit të tyre demonstrohet në një raport i vitit 2020 nga DataReportal, një platformë online që analizon se si bota përdor internetin.
Në janar, kishte rreth 3.7 milionë përdorues të rrjeteve sociale në Serbi, 1.1 milion në Maqedoninë e Veriut, 390,000 në Mal të Zi dhe 1.7 milion në Bosnjë dhe Hercegovinë.
Në secilin prej vendeve, Facebook është më i popullarizuari, me rreth tre milionë përdorues në Serbi, 970,000 në Maqedoninë e Veriut, 300,000 në Mal të Zi dhe 1.4 milion në Bosnjë dhe Hercegovinë.
Shifra të tilla i bëjnë vendet e Ballkanit tërheqëse për reklama, por edhe për përhapjen e mesazheve politike, duke hapur portën edhe për shkelje.
Debati mbi përfitimet dhe rreziqet e rrjeteve sociale për shoqërinë e shekullit XXI është i njohur. Sa i përket përmbajtjes së dhunshme, përveç përdorimit të Inteligjencës Artificiale, AI, gjigantët e rrjeteve sociale po përpiqen t’u japin përdoruesve mjetet për të reaguar gjithashtu, kryesisht duke raportuar shkelje tek administratorët e rrjetit.
Ekzistojnë tre lloje filtrash – filtrimi manual nga njerëzit; filtrim i automatizuar nga mjete algoritmike dhe filtrim hibrid, i kryer nga një kombinim i njerëzve dhe mjeteve të automatizuara.
Në raste pasigurie, postimet ose llogaritë i nënshtrohen rishikimit njerëzor para se të merren vendime, ose pasi në rast se një përdorues ankohet në lidhje me heqjen automatike.
“Sot, ne mbështetemi kryesisht te AI për zbulimin e përmbajtjes shkelëse në Facebook dhe Instagram, dhe në disa raste për të ndërmarrë veprime mbi përmbajtjen edhe në mënyrë automatike”, tha për BIRN një zëdhënës i Facebook. “Ne përdorim rishikues të përmbajtjes për të shqyrtuar dhe etiketuar përmbajtje specifike, veçanërisht kur teknologjia është më pak efikase në kuptimin e kontekstit, qëllimit ose motivimit.”
Twitter tha për BIRN se po shton përdorimin e automatizimin për të zbatuar rregullat.
“Sot, duke përdorur teknologjinë, më shumë se 50 për qind e përmbajtjes abuzive që merret përsipër nga shërbimi jonë shfaqet në mënyrë aktive për rishikim njerëzor në vend që të mbështetet në raportime nga njerëzit që përdorin Twitter”, tha një zëdhënës i kompanisë.
“Ne kemi ekipe të fuqishme dhe të përkushtuara specialistësh të cilët ofrojnë mbulim global 24/7 në shumë gjuhë të ndryshme dhe ne po ndërtojmë më shumë kapacitete për të adresuar çështje gjithnjë e më komplekse.”
Në mënyrë që të kontrollohet se sa efikase janë ato mekanizma kur bëhet fjalë për përmbajtjen në gjuhët ballkanase, BIRN kreu një studim që përqendrohej në raportime në Facebook dhe Twitter dhe i ndau në tre kategori: kërcënime të dhunshme (direkte ose indirekte), ngacmime dhe sjellje urryese.
Sondazhi kërkoi gjuhën e përmbajtjes së diskutueshme, kush ishte shënjestra dhe kush ishte autori, dhe nëse raportimi ishte i suksesshëm apo jo.
Mbi 48 për qind e të anketuarve raportuan gjuhë urrejtjeje, rreth 20 për qind raportuan ngacmime të synuara dhe rreth 17 për qind raportuan kërcënime dhune.
Sondazhi tregoi se njerëzit ishin më të gatshëm të raportonin përmbajtje që synonte ata ose grupet e pakicave.
Sipas sondazhit, 43 për qind e përmbajtjes së raportuar si gjuhë urrejtjeje mbetej në internet, ndërsa 57 për qind u hoq. Kur bëhet fjalë për raportime dhune kërcënuese, përmbajtja u hoq në 60 për qind të rasteve.
Afërsisht gjysma e raportimeve të ngacmimeve të shënjestruara u hoqën.
Chloe Berthelemy, një këshilltare politikash në European Digital Rights, EDRi, e cila punon për të promovuar të drejtat digjitale, thotë se pasojat në jetën reale të neglizhencës mund të jenë katastrofike.
“Për shembull, në rastet e abuzimit seksual të bazuar tek imazhi (shpesh i quajtur gabimisht “pornografi hakmarrëse), shumica e viktimave janë gra dhe ato vuajnë nga përjashtimi social si rezultat i këtyre sulmeve”, tha Berthelemy në një përgjigje me shkrim për BIRN . “Për shembull, ato mund të diskriminohen në tregun e punës sepse rekrutuesit kërkojnë reputacionin e tyre në internet.”
Heqja e përmbajtjes – censurë apo korrigjuese?
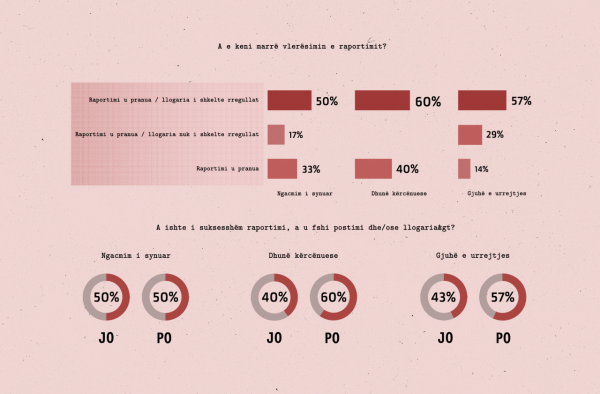
Sipas përgjigjeve ndaj pyetësorit të BIRN, rreth 57 për qind e atyre që raportuan gjuhë urrejtje thanë se ishin njoftuar që postimi/llogaria e raportuar shkelte rregullat.
Nga ana tjetër, rreth 28 për qind thanë se kishin marrë njoftim se përmbajtja që ata raportuan nuk shkelte rregullat, ndërsa 14 për qind morën vetëm konfirmimin se raportimi i tyre ishte dorëzuar.
Sa i përket raportimeve të ngacmimeve të synuara, gjysma e njerëzve thanë se kishin marrë konfirmim se përmbajtja shkelte rregullat; 16 për qind njerëzve iu tha se përmbajtja nuk shkelte rregullat. Një e treta e atyre që raportuan ngacmime të synuara morën vetëm konfirmimin se raportimi i tyre ishte dorëzuar.
Sa i përket kërcënimit të dhunës, 40 për qind e njerëzve morën konfirmimin se postimi/llogaria e raportuar shkelte rregullat ndërsa 60 për qind morën vetëm konfirmimin se ankesa e tyre ishte dorëzuar.
Një nga të anketuarit i tha BIRN se ata kishin raportuar të paktën shtatë llogari për përhapje urrejtjeje dhe përmbajtjeje të dhunshme.
“Unë nuk angazhohem aktivisht në raportime të tilla dhe nuk vazhdoj as t’i shikoj dhe as t’i kërkoj ato. Megjithatë, kur has një nga këta mohues të urryeshëm të gjenocidit dhe mbështetës të gjenocidit, ndihen se kjo është gjëja e duhur për të bërë, për të ndaluar që një përmbajtje e tillë të shkojë më tej”, tha i anketuari, duke folur në kushte anonimiteti. “Ndoshta një nga të gjithë individët e raportuar ndalon dhe pyet veten se çfarë ishte ajo që çoi në këtë pikë dhe thjesht hap diskutime, me veten ose qarqet e tyre.”
Edhe pse për ato shtatë llogari Twitter konfirmoi se shkelnin disa nga rregullat, gjashtë prej tyre janë ende të disponueshme në internet.
Një tjetër problem që u shfaq është kriteret e paqarta gjatë raportimit të shkeljeve. Kërkohet gjithashtu njohuri themelore e gjuhës angleze.
Sanjana Hattotuwa, themeluese e Groundviews, faqja e parë e gazetarisë qytetare në Sri Lanka, dhe një studiuese mbi shkrimin dhe leximin e medieve të reja, aktivizmin e internetit, sigurinë digjitale dhe avokimin online, ra dakord që procesi i raportimit në aplikacion ose online është i ngatërruar.
“Për më tepër, shpesh është në anglisht edhe pse pjesa tjetër e UI/UX (Ndërfaqja e Përdoruesit/Përvoja e Përdoruesit) mund të jetë në gjuhën lokale. Për më tepër, zgjedhja e mundimshme e kategorive nuk është aspak e lehtë, sidomos kur është me detyrim.”
Facebook i tha BIRN se shumica dërrmuese e raportimeve shqyrtohen brenda 24 orësh dhe se kompania përdor raportimin e komunitetit, rishikimin njerëzor dhe automatizimin.
Megjithatë, Facebook refuzoi të jepte ndonjë specifikë mbi ata që punëson për të rishikuar përmbajtjen ose raportet në gjuhët ballkanase, duke thënë “nuk është e saktë të japësh vetëm numrin e vlerësuesve të përmbajtjes”.
“Vetëm kjo nuk pasqyron numrin e njerëzve që punojnë në një rishikim përmbajtjeje për një vend të caktuar në një kohë të caktuar”, tha zëdhënësi.
Rrjetet sociale shpesh e heqin vetë përmbajtjen, në atë që ata e quajnë një ‘qasje proaktive’.
Sipas të dhënave të siguruara nga Facebook, në tremujorin e fundit të vitit 2017 shkalla e tyre e zbulimit proaktiv ishte 23.6 për qind.
“Kjo do të thotë që nga gjuha e urrejtjes që kemi hequr, 23.6 për qind e saj është gjetur para se një përdorues të na e raportonte”, tha zëdhënësi. “Pjesa më e madhe e mbetur u hoq pas raportimit nga ana e një përdoruesi. Sot ne zbulojmë në mënyrë aktive rreth 95 për qind të përmbajtjes së gjuhës së urrejtjes që heqim.”
“Pavarësisht nëse përmbajtja zbulohet ose raportohet në mënyrë aktive nga përdoruesit, ne shpesh përdorim AI për të ndërmarrë veprime në raste të drejtpërdrejta dhe për t’i dhënë përparësi rasteve më të nuancuara, ku duhet të merret parasysh konteksti, për shqyrtuesit tanë.”
Megjithatë, nuk ka të dhëna të disponueshme kur bëhet fjalë për përmbajtje në një gjuhë ose vend të caktuar.
Facebook publikon çdo tre muaj një Raport Zbatimi të Standardeve të Komunitetit, por, sipas zëdhënësit, kompania nuk “zbulon të dhëna në lidhje me moderimin e përmbajtjes në vende të veçanta”.
Pavarësisht nga mjetet, rezultatet ndonjëherë janë shumë të dyshimta.
Në maj 2018, Facebook bllokoi për 24 orë profilin e gazetarit boshnjak Dragan Bursac pasi ai postoi një foto të një kampi paraburgimi për boshnjakët në Serbi gjatë shpërbërjes së Jugosllavisë federale në vitet 1990.
Facebook përcaktoi se postimi i Bursac kishte shkelur “standardet e komunitetit”, raportuan mediat lokale.
Bojan Kordalov, specialist për marrëdhëniet me publikun në Shkup dhe specialist i mediave të reja, tha se, “kur vlerëson efikasitetin në këtë fushë, është e rëndësishme të theksohet se trafiku në hapësirën e Internetit është shumë i dendur dhe po rritet çdo sekondë, gjë që e bën atë pa dyshim një fushë ku të gjithë duhet të kontribuojnë ”.
“Kjo do të thotë që menaxherët e rrjeteve sociale janë në mënyrë të padiskutueshme përgjegjës për përmbushjen e standardeve dhe për pajtueshmërinë me rregulloret brenda platformave të tyre, por kjo nuk çliron nga çdo detyrim ligjvënësit, qeveritë dhe institucionet e përgjegjësisë në përshtatjen me nevojat e epokës së re digjitale, dhe as nuk i jep askujt e drejta për të ripërcaktuar dhe ngushtuar nocionin dhe përfitimet që sjell demokracia.”
Mungesë ndjeshmërie gjuhësore

Fondacioni SHARE, një OJQ me bazë në Beograd që punon për të drejtat digjitale, tha se pyetja ishte thelbësore duke pasur parasysh vëllimin e madh të përmbajtjes që rrjedh përmes faqeve të ngjashme në Facebook dhe Twitter në të gjitha gjuhët.
“Kur bëhet fjalë për grupe relativisht të vogla gjuhësh në shifra absolute përdoruesish, të tilla si gjuhët në ish-Jugosllavi apo edhe në Ballkan, thjesht nuk ka asnjë nxitje ose presion të mjaftueshëm nga publiku dhe liderët politikë për të investuar në moderim njerëzor”, tha SHARE për BIRN.
Bertelemy e EDRi tha se Ballkani nuk ishte një shembull i vetëm dhe se praktikat dhe politikat e moderimit të përmbajtjes të Facebook dhe Twitter janë “të dënuara të dështojnë”.
“Shumë prej këtyre korporatave operojnë në një shkallë masive, disa prej tyre duke u shërbyer deri në një të katërtës së popullsisë së botës me një shërbim të vetëm”, tha Berthelemy për BIRN. “Është e pamundur që një arkitekturë e tillë monolitike dhe procesi edhe politika e rregullimit të fjalës të akomodojë dhe plotësojë nevojat specifike kulturore dhe shoqërore të individëve dhe grupeve.”
Parlamenti Evropian gjithashtu ka theksuar rëndësinë e një vlerësimi të kombinuar.
“Shprehjet e urrejtjes mund të përcillen në shumë mënyra dhe të njëjtat fjalë që përdoren zakonisht për të përcjellë shprehje të tilla mund të përdoren gjithashtu për qëllime të ndryshme”, sipas një studimi të vitit 2020 – “Ndikimi i algoritmeve për filtrimin ose moderimin e përmbajtjes në internet” – porositur nga Departamenti i Politikave i Parlamentit për të Drejtat e Qytetarëve dhe Çështjet Kushtetuese.
“Për shembull, fjalë të tilla mund të përdoren për të dënuar dhunën, padrejtësinë ose diskriminimin ndaj grupeve të synuara, ose thjesht për të përshkruar rrethanat e tyre shoqërore. Kështu, për të identifikuar përmbajtjen urryese në mesazhet me tekst, duhet të bëhet një përpjekje për të kuptuar kuptimin e këtyre mesazheve, duke përdorur burimet e siguruara nga përpunimi i gjuhës natyrore.”
Hattotuwa tha se, në përgjithësi, “tregjet në gjuhën jo-angleze me shkrime jo romane (pra, jo me bazë shkronjash angleze) janë shumë më të vështira për të hartuar zgjidhje AI/ML”.
“Dhe në shumë raste, këto tregje janë larg syve dhe larg mendjes, përveç rasteve nëse dhuna, abuzimi ose dëmtimet e platformës janë aq të rëndësishme sa prekin faqen e parë të New York Times“, tha Hattotuwa për BIRN.
“Njerëzit janë të nevojshëm për vlerësime, por siç e dini, ka çështje serioze emocionale/PTSD në lidhje me mbikëqyrjen e përmbajtjes së dhunshme, për të cilat kompani si Facebook janë paditur (dhe kanë humbur, duke u paguar dëmshpërblime).”
Dështim në gjuhët që nuk janë anglisht

Dragan Vujanovic i OJQ-së me seli në Sarajevë “Vasa Prava” (Të Drejtat Tuaja) kritikoi atë që ai tha se ishte “një nivel i caktuar tolerance në lidhje me shkeljet që mbështesin narrativa të caktuara shoqërore”.
“Kjo është veçanërisht e dukshme në sjelljen jo konsistente të moderatorëve të rrjeteve sociale ku llogaritë me komente deri diku të padëmshme ndalohen ose pezullohen ndërsa llogaritë e tjera, me abuzim të dukshëm dhe ndikim të qartë negativ shoqëror, tolerohen.”
Për Chloe Berthelemy, përpjekja për të zbatuar një grup rregullash uniforme për gamën shumë të larmishme të normave, vlerave dhe mendimeve për të gjitha temat në dispozicion që ekzistojnë në botë “është e thënë të dështojë”.
“Për shembull, ku lakuriqësia konsiderohet si një temë e ndjeshme në Shtetet e Bashkuara, kulturat e tjera marrin një qasje më liberale”, tha ajo.
Shembulli i Mianmarit, kur Facebook në mënyrë efikase bllokoi një gjuhë të tërë duke refuzuar të gjitha mesazhet e shkruara në Jinghpaë, një gjuhë e folur nga kaçinat etnikë të Mianmarit dhe e shkruar me një alfabet romak, tregon shkallën e problemit.
“Platforma ka një performancë shumë të dobët në zbulimin e gjuhës së urrejtjes në gjuhët e tjera që nuk janë anglisht”, tha Berthelemy për BIRN.
Teknikat e përdorura për të filtruar përmbajtjen ndryshojnë në varësi të mediave të analizuar, sipas studimit të vitit 2020 për Parlamentin Evropian.
“Një filtër mund të funksionojë në nivele të ndryshme kompleksiteti, duke filluar nga krahasimi i thjesht i përmbajtjeve kundër një liste të zezë, te teknikat më të sofistikuara duke përdorur teknika komplekse të AI”, tha ai.
“Në qasjet e mësimit makinerik, sistemit, në vend që t’i sigurohet një përkufizim logjik i kritereve që do të përdoren për të gjetur dhe klasifikuar përmbajtjen (p.sh., për të përcaktuar se çfarë llogaritet si gjuhë urrejtjeje, shpifje, etj.) i ofrohet një grup të dhënash, nga të cilat duhet të mësojë vetë kriteret për të bërë një klasifikim të tillë.”
Përdoruesit Twitter dhe Facebook mund të apelojnë në rast se llogaritë e tyre pezullohen ose bllokohen.
“Për fat të keq, procesit i mungon transparenca, pasi numri i ankesave të paraqitura nuk përmendet në raportin e transparencës, as numri i llogarive dhe postimeve të përpunuara ose të rihapura”, vuri në dukje studimi.
Midis janarit dhe tetorit 2020, Facebook riktheu 50,000 artikuj përmbajtjeje pa apelim dhe 613,000 pas apelimit.
Sipas raportit të Transparencës të Twitter, në gjashtë muajt e parë të vitit 2020, 12.4 milionë llogari u raportuan te kompania, pak më shumë se gjashtë milion prej të cilave u raportuan për sjellje urrejtjeje dhe rreth 5.1 milion për “abuzim/ngacmim”.
Në të njëjtën periudhë, Twitter pezulloi 925,744 llogari, nga të cilat 127,954 u shënuan për sjellje urrejtjeje dhe 72,139 për abuzim/ngacmim. Kompania hoqi përmbajtje të tillë në pak më shumë se 1.9 milion raste: 955,212 në kategorinë e sjelljes së urryeshme dhe 609,253 në kategorinë e abuzimit/ngacmimit.
Toskic Cvetinovic tha se rregullat duhej të ishin më të qarta dhe t’u komunikoheshin më mirë përdoruesve nga “njerëzit e gjallë”.
“Shpesh, heqja e përmbajtjes nuk ka një funksion korrigjues, por arrin në censurë”, tha ajo.
Berthelemy tha se, “për shkak se platformat mbizotëruese të rrjeteve sociale riprodhojnë sisteme shoqërore shtypjeje, ato janë gjithashtu shpesh të pasigurta për shumë grupe”.
“Ata nuk janë në gjendje të kuptojnë sjelljet diskriminuese dhe të dhunshme në internet, duke përfshirë forma të caktuara ngacmimi dhe kërcënimesh të dhunshme dhe për këtë arsye, nuk mund të adresojnë nevojat e viktimave”, tha Berthelemy për BIRN.
“Për më tepër,” tha ajo, “ato rrjete mediash sociale janë gjithashtu kompani reklamash. Ata mbështeten në përmbajtje inflamatore për të gjeneruar të dhëna profilizimi dhe kështu fitime nga reklamat. Nuk do të ketë përgjigje efikase dhe sistematike pa adresuar modelet e biznesit të akumulimit dhe tregtimit të të dhënave personale.”
Mësimi makinerik
Siç citohet në studimin e vitit 2020 të porositur nga Parlamenti Evropian, Facebook ka zhvilluar një qasje të quajtur Whole Post Integrity Embeddings, WPIE, për t’u marrë me përmbajtjen që shkel udhëzimet e Facebook.
Sistemi adreson përmbajtjen multimediale duke siguruar një analizë holistike të përmbajtjes vizuale dhe tekstuale të një postimi dhe komenteve të lidhura, në të gjitha dimensionet e papërshtatshmërisë (dhunë, urrejtje, lakuriqësi, drogë, etj.). Kompania pretendon se mjetet e automatizuara kanë përmirësuar zbatimin e udhëzimeve të përmbajtjes në Facebook. Për shembull, rreth 4.4 milion artikuj që kishin në përmbajtje shitje droge u hoqën vetëm në tremujorin e tretë të vitit 2019, 97.6 për qind e të cilave u zbuluan në mënyrë aktive.
Kur bëhet fjalë për mënyrat në të cilat rrjetet sociale trajtojnë përmbajtje të dyshimtë, Hattotuwa tha se “konteksti është thelbësor”.
Ndërsa pranoi përparimet e bëra në dy-tre vitet e fundit, Hattotuwa tha se, “Asnjë AI dhe ML, mesa di unë, madje edhe në gjuhën angleze kontekstet nuk mund të identifikojnë me saktësi kuptimin pas një imazhi”.
“Në lidhje me përmbajtjen që nxit urrejtje, lëndim dhe dëmtim”, tha ai, “sfida është edhe më e madhe.”
Metodologjia e BIRN
BIRN e zhvilloi pyetësorin e tij nëpërmjet mjetit të rrjetit për angazhimin e qytetarëve në raportim, të zhvilluar në bashkëpunim me British Council.
Pyetësori anonim kishte për qëllim mbledhjen e informacioneve mbi llojin e shkeljeve që raportonin njerëzit, kush ishte shënjestra dhe sa i suksesshëm ishte raportimi. Pyetjet ishin në dispozicion në anglisht, maqedonisht, shqip dhe në gjuhën boshnjake/serbisht/malazeze. BIRN u përqendrua te Facebook dhe Twitter duke pasur parasysh popullaritetin e tyre në Ballkan dhe ndjeshmërinë e përmbajtjes së përbashkët, e cila është kryesisht tekstuale dhe më e vështirë për t’u vlerësuar në krahasim me videot dhe fotografitë.